
|
|
|
I am a graduate student at Mila working with Prof. Golnoosh Farnadi on Responsible AI (Fairness and Privacy in ML)! Previously, I was Research Manager at the PathCheck Foundation (MIT Media Lab spin-off) advised by Prof. Ramesh Raskar where I worked on privacy preserving machine learning, adversarial representation learning, and graph neural networks with applications in computational health. Additionally, I co-founded the Data Informatics Center for Epidemiology (DICE) along with Prof. Ramesh Raskar (MIT), Prof. Manuel Morales (University of Montreal, Quebec) and Prof. Sue Feldman (University of Alabama at Birmingham). I also hosted the Global Health Innovators Seminar, where we bring in speakers who use AI and Computer Science to create societal impact (particulary in healthcare). Feel free to check out my CV and drop me an e-mail if you want to chat with me! ~ Email | CV | Google Scholar | Medium | Github | LinkedIn | Twitter ~ |
|
Feb '24 |
I am a recipent of the Mila Excellence in Research Awards for my work in Responsible AI! |
|
Jan '24 |
Our paper Balancing Act: Constraining Disparate Impact in Sparse Models got accepted to ICLR-24! See you in Vienna! |
|
Oct '23 |
Chekout my latest paper Balancing Act: Constraining Disparate Impact in Sparse Models on arXiv. |
|
Jun '23 |
My paper Omega - Optimistic EMA Gradients got accepted as an Oral presentation in LXAI workshop @ ICML-23 |
|
Aug '22 |
Joined Mila and UdéM as Research MSc student, working with Prof. Golnoosh Farnadi on Responsibile AI |
|
Jan '22 |
Check out my blog based on Prof. Milind tambe's talk at the Global Health Innovators event I host here. Video of the talk can be found here! |
|
Nov '21 |
I gave an invited talk, on our privacy-preserving crowdsourced computational health toolkit, at IIIT Bangalore for the ML and Cognition course taught by Prof. G N Srinivasa Prasanna. Video for the talk can be found here! |
|
Nov '21 |
We officially launched the Data Informatics Center for Epidemiology! I am currently serving as the founding Deputy Director for Scientific Programs (Research). Check out more details here! |
|
Oct '21 |
My paper on using weak-supervison and semi-supervised ditilation to build robust and scalable transformer models got accepted into CODS-COMAD. Camera-ready version! |
|
Aug '21 |
My work on "Fake News" detection with Dr. Sundeep Teki got Featured in the IIT Madras Shastra Magazine. Check out the full article here. Check out the paper here, it was previously accepted at the AAAI 2021 CONSTRAINT workshop! |
|
Aug '21 |
Check out my new pre-print on using Clinical Search Trends data from TATA-1mg to predict upcoming waves in the pandemic (with a lead of upto 21 days). This work is currently under review at JAMIA! |
|
Aug '21 |
Our solution on privacy-preserving, crowdsourced pandemic preparedness and response selected amongst 14 finalists among 3000+ applicants globally at the MIT SOLVE Health Securites and Pandemic Challenge! |
|
Jun '21 |
Got funding to attend ICML 2021 and MLHC 2021. See you all there! |
|
Jun '21 |
Paper accepted as Oral presentation at AI4SG Workshop at IJCAI '21! Check out the preprint! |
|
May '21 |
We are one of the Highly Commended Solutions at Trinity Challenge among 350+ global applicants. Check out the detailed solution at GitBook or MIT Solve! |
|
May '21 |
Paper accepted in the Journal of Behavioural Data Science. Check out the paper here! |
|
Mar '21 |
We are among the finalists in the Rapid Response challenge for our work on vaccine credintials. |
|
Jan '21 |
We are among the top 10 teams in the XPRIZE Pandemic Response Challenge and we have now moved to the finals. Check out the code here. |
|
Dec '20 |
I started as Research Manager at PathCheck Foundation, under the guidence of Prof. Ramesh Raskar. I would be co-leading the data science and privacy teams to build computational health solutions! |
|
Dec '20 |
We are one of the Finalists in the Facebook Data For Good - Symptoms Data Challenge. Check out presentation video! |
|
Nov '20 |
Our paper on using Bluetooth RSSI Low Energy Signals and other mobile sensor information for contact tracing got accepted to the ML4MH workshop at NeurIPS 2020. Find the paper here. |
|
May '20 |
Pushed a scalable deep learning model to production, using weak supervison, knowledge distilation and semi-supervised learning. Check out our preprint to know more about the work! |
|
Mar '20 |
Got a letter of appreciation from Google AI for being one of the top facilitators of the cohort! Check the letter out here |
|
Feb '20 |
My project on Diabetic Retinopathy detection got selected as one of the 20 projects from across India for Google AI Bootcamp! Check out the repo here! |
|
Jan '20 |
I started as Research Scientist Intern at Applied Research, Swiggy, under the guidence of Dr. Sundeep Teki. I would be working on semi-supervised learning and weak supervision in NLP! |
|
Jun '19 |
Selected as a member of the inaugral cohort of Google AI Explore ML Facilitator, India |
|
Mar '19 |
Presented my work on building computational solutions for early detection of diabetic retinopathy for the subaltern at IIM Kozhikode, GLoHMT conference. Code can be found here. |
|
Mar '19 |
My paper on societal impacts of AI and Social Media, along with researchers from IIM Trichy got accepted to the 35th EGOS Colloquium (<10 % acceptance rate). |
|
|
Aug '22 - Present Working with Prof. Golnoosh Farnadi on Privacy-Preserving ML and Fairness in ML! |
|
|
June '21 - Present Working with Prof. Manuel Morales , Prof. Ramesh Raskar and Prof. Sue Feldman at DICE center at PathCheck Foundation. |

|
Dec '20 - Aug '22 Working under the supervision of Prof. Ramesh Raskar and at the PathCheck Foundation. We are working on building robust, scalable and secure computational health models |
|
|
Jan '20 - Nov '20 Worked as Research Scientist Intern at Applied Research, Swiggy, under the guidence of Dr. Sundeep Teki. I worked on semi-supervised learning and weak supervision for code-mixed/multilingual customer interaction classification problems (NLP) |

|
Jun'19 - Mar '20 Was part of the inaugral cohort of the Google AI Explore ML Program in India. I was one among the 120 facilitators selected across India from 3000+ applicants. As part of the program I have trained 700+ students on various paradigms of machine learning (NLP, CV and DL) - on basic, moderate and advanced curriculum. This was a volunteer based program. I recieved appreciation letter from Google AI for being one of the top facilitators. Please find the letter here. |

|
Aug '18 - Dec '19 Worked as Teaching Assistant for 3 core CS courses. Information Retrieval - worked with Prof. Rajendra Prasath, as the only TA for the course. mentored 10+ teams for course projected and was involved in doubt clearance sessions. Database Management Systems - worked with Prof. Prerana Mukherjee, as the one among 2 TAs for the course. Conducted 13 - 2 hour tutorial sessions, mentored 20+ teams on the course project - link to repo. Programming in C - worked with Prof. Venkatesh Vinayakarao, as the one among 13 TAs for the course. Was involved in running twelve 3 hour lab sessions and creating problems for weekly lab evaluations. |
| Under construction. Please check my Google Scholar or CV for the complete list of papers! |
|
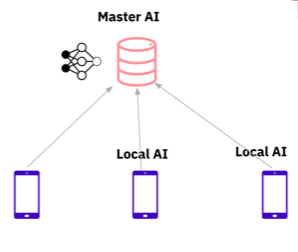
Under submission. In this paper, we tackle the question of how to benchmark reconstruction of inputsfrom deep neural networks (DNN) representations. This inverse problem is of great importance in the privacy community where obfuscated representation has been proposed as a technique for privacy-preserving machine learning (ML) inference. In this benchmark, we characterize different obfuscation techniques and identify different attack models. We propose multiple reconstruction techniques based upon distinct background knowledge of the adversary. We have open-sourced and constantly updating the code, dataset, hyper-parameters, and trained models that can be found at link. |
|
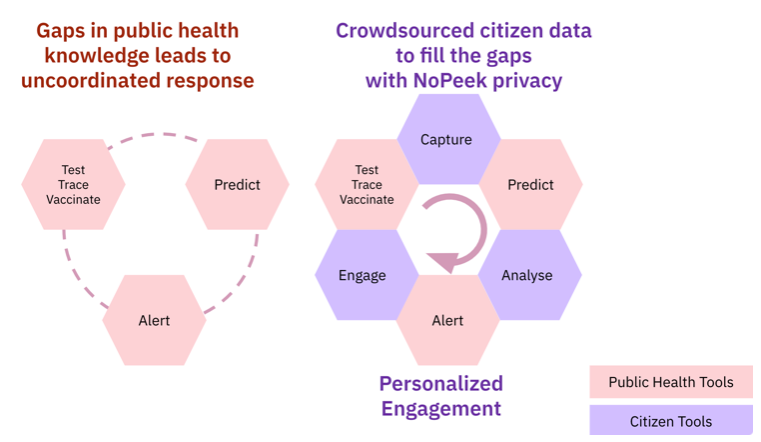
Working towards open-source toolkit (Link coming soon) Crowdsourced citizen data can complement and connect incomplete and fragmented data that cripples pandemic responses. But, large-scale participation requires citizens’ trust and engagement. We solve this with a unique “NoPeek” privacy and personalization delivered with a free, open-source toolkit for governments and large institutions. Our solution - A novel open-source computational privacy software from MIT and PathCheck that captures crowdsourced health information, analyzes it for public and precision health, and engages users via personalized recommendations. We provide computational techniques to handle the five steps of the pandemic progress - exposure, symptoms onset, test, treatment, and vaccination. The four main technologies that we use in no-peek primarily are minimum upload exposure notification, secure multi-party computation, differential privacy, and federated or split learning. Link to GitBook. |
|
Working towards building an open-source framework Generative models of differential privacy are becoming popular, to synthesize artificial private datasets. These models are seeded with non-private datasets as an input. Private synthetic datasets enable data publishing and consolidation for the purpose of training machine learning models. At the same time, differentially private models for performing machine learning tasks are being actively developed as well. In this paper we study how these two approaches can feed into each other in a mutually beneficial manner. We learn private models to predict one variable in a dataset at a time from rest of the variables using differentially privacy. We obtain the results and ensemble them to get an improved model for private data synthesis, given that ensembling with bootstrapping naturally gives differential privacy under some assumptions. We also use generative models to generate private synthetic data that are fed into non-private machine learning model ensembles; by exploiting the post-processing invariance properties of differential privacy. We finally perform a meta-ensemble of the above two ensembles to study its performance. We thoroughly study the privacy-utility tradeoffs of these approaches to conclude that such ensembles complement each other in a win-win relationship. Link to code (work in progress). |
|
Working towards submission at the British Medical Journal (BMJ) Agent based models (ABMs) are highly expressive simulation models. Even then, they suffer from (i)scalability (number of agents/time to run the simulation), and (ii) the inability to perform gradient-based optimization (learning in a data-driven way). Recent work from Chopra et al (2021), circumvents these issues by utilizing Graph Neural Networks to build highly expressive ABMs - DeepABM. Presently, I am extending this work by introducing various macro and micro level data, in collaboration with graduate students of Prof. Ramesh Raskar and Prof. B. Aditya Prakash. Our solution aims to interpret disease specifc parameters in an end-to-end data-driven mechanism. |
|
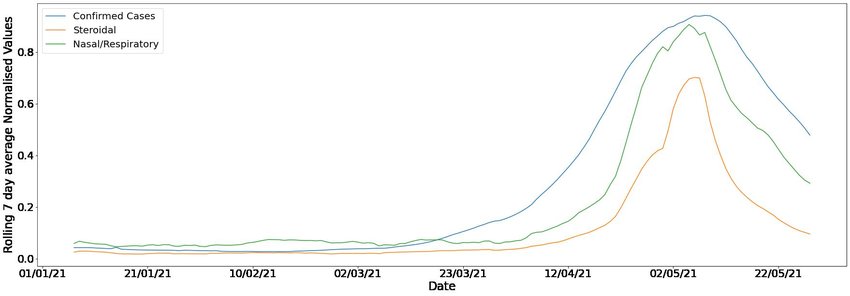
Working towards submission at JAMIA Objective: Severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) is the cause of the ongoing Covid-19 pandemic which is having devastating effects around the globe. Identifying early indicators of case surges is pivotal for effective pandemic preparedness and response. In this paper, we look at Tata-1mg users' medicine and symptom search data in India, and study its potential to provide early warning of upcoming waves in the current pandemic. Methods and Materials: Tata-1mg is an online healthcare brand present in India, with 50 million monthly active users, that allows users to search and order medicines. We segment different search terms with the help of clinical practitioners used by the customers based on their association with illness and severity and then assess their correlation with reported Covid-19 case numbers for Indian cities. Results: We found that the search terms relating to flu/antiviral medication had the highest leading correlation among all seven search tags tested. We also perform a granular, city level cross correlation analysis for 75 Indian cities. We show that the search terms had up to an average of 19 days prior lead (ranging between 0, 40 days) with significant Pearson correlations (R=0.7, p<0.01) with reported Covid-19 case numbers for most cities. Conclusion: We can use information from search data to formulate better healthcare policies to control the coronavirus pandemic outbreak in the future as well as stock adequate resources. We highlight the ability of search trend data of online pharmaceutical e-commerce platforms to serve as an early warning indicator for future waves. Link to pre-print. |
|
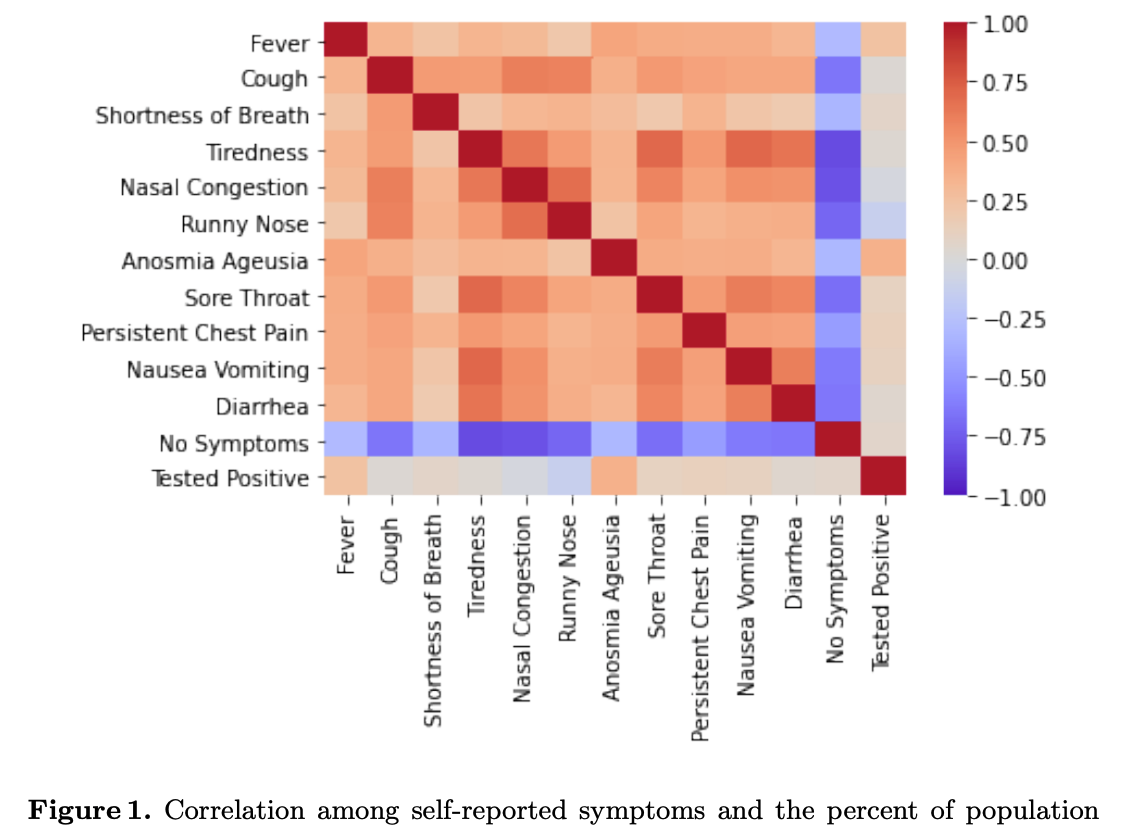
Papers accepted in AI4SG Workshop IJCAI and the Journal of Behavioural Data Science The COVID-19 pandemic has impacted lives and economies across the globe, leading to many deaths. While vaccination is an important intervention, its roll-out is slow and unequal across the globe. Therefore, extensive testing still remains one of the key methods to monitor and contain the virus. Testing on a large scale is expensive and arduous. Hence, we need alternate methods to estimate the number of cases. Online surveys have been shown to be an effective method for data collection amidst the pandemic. In this work, we develop machine learning models to estimate the prevalence of COVID-19 using self-reported symptoms. Our best model predicts the daily cases with a mean absolute error (MAE) of 226.30 (normalized MAE of 27.09%) per state, which demonstrates the possibility of predicting the actual number of confirmed cases by utilizing self-reported symptoms. The models are developed at two levels of data granularity - local models, which are trained at the state level, and a single global model which is trained on the combined data aggregated across all states. Our results indicate a lower error on the local models as opposed to the global model. In addition, we also show that the most important symptoms (features) vary considerably from state to state. This work demonstrates that the models developed on crowd-sourced data, curated via online platforms, can complement the existing epidemiological surveillance infrastructure in a cost-effective manner. Code available here and here. Papers can be found here and here. |
|
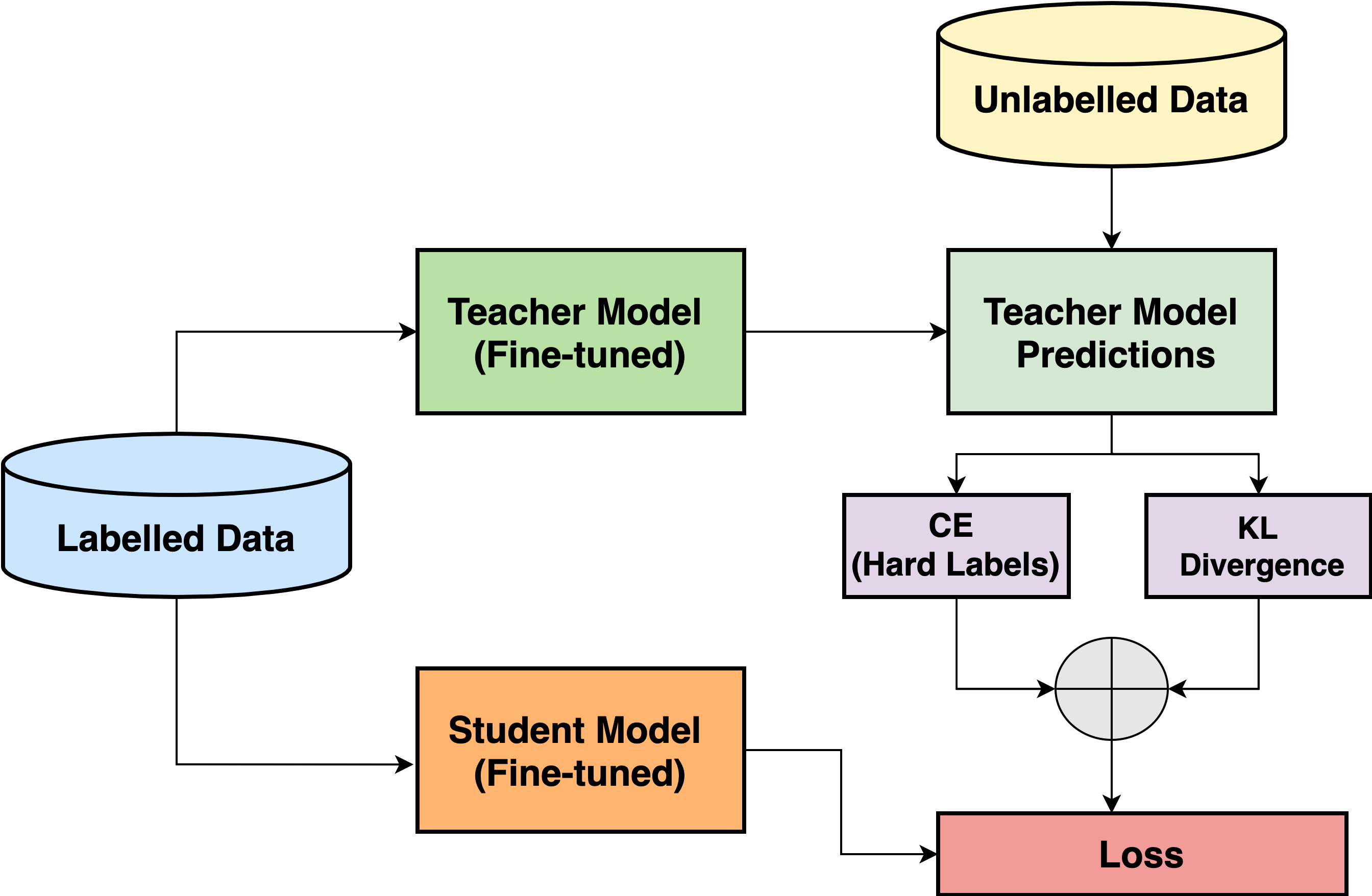
Papers accepted in ACM CODS-COMAD (<21 % acceptance rate) Text Classification has a variety of applications in the pickup and delivery services industry where customers require one or more items to be picked up from a location and delivered to a certain destination. Categorizing these customer transactions helps understand the market needs and trends while also assisting in building a personalized experience for each customer segment. In this paper, each transaction is accompanied by a free text description provided by the customer to describe the products to be picked up and delivered. These descriptions tend to be short, incoherent and code-mixed (Hindi-English) text. Here, we focus on a specific use-case where each customer transaction can be mapped to a single product category. We propose a cost-effective transaction classification approach based on proxy-labelling and knowledge distillation using the transaction descriptions provided by the customer. We introduce R-ALBERT, a model trained with RoBERTa as the "teacher" and ALBERT (33x fewer parameters than RoBERTa) as the "student". Further, we benchmark R-ALBERT on a large internal dataset as well as the 20Newsgroup dataset. We see that our model shows a 2% increase in performance with 33x fewer parameters. The model is currently deployed in production and is helping understand the customer behaviour across product categories and customer segments. |
|
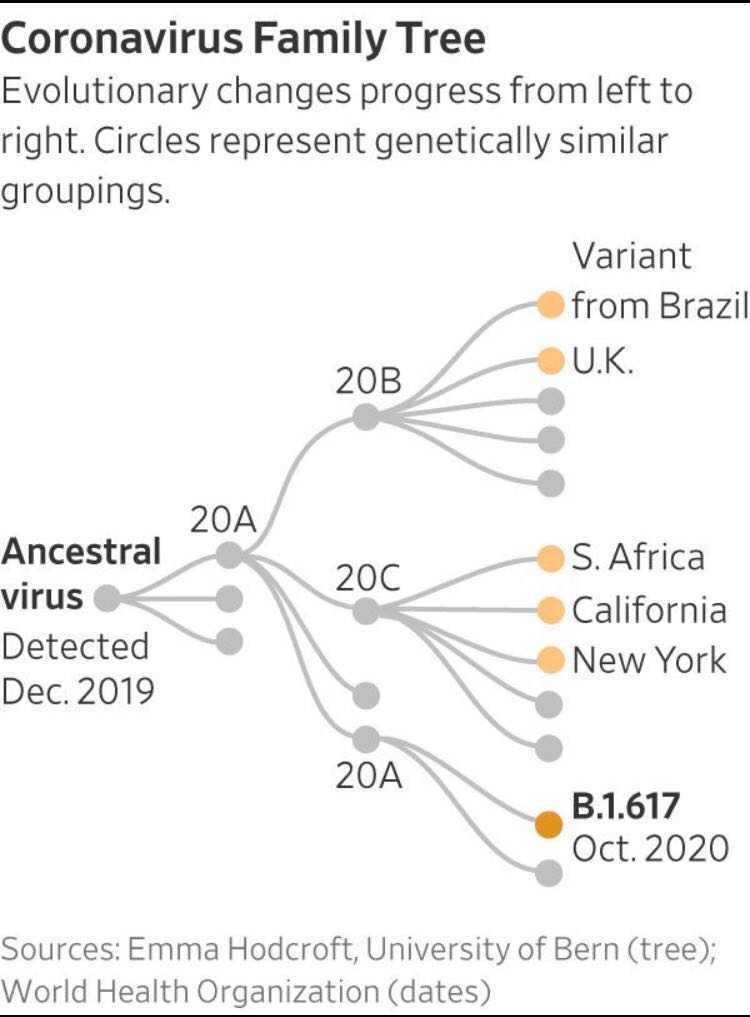
Working towards submission at the British Medical Journal (BMJ) To investigate the deviation of COVID-19 case declines from predicted rates in the US in relationship to viral variants and mutations. In this work we focus on analysing the differential impact of variants (B.1.526 and B.1.526.2) COVID-19 cases and hospitalisations in New York. Our initial analysis show that these variants have immune escape pottential and could be the reason for rise in cases. |
|
Paper accepted at the ML4MH workshop at NeurIPS 2020 Despite the discovery of vaccines, social-distancing via efficient contact tracing has remains one of the primary health strategy to dampen the spread of COVID-19. To enable efficient digital contact tracing, we present a novel system to estimate pair-wise individual proximity, by jointly modeling Bluetooth Low Energy (BLE) signals with other on-device sensors (accelerometer, magnetometer, gyroscope). We explore multiple ways of interpreting the sensor data stream (time-series, histogram, etc) and use several statistical and deep learning methods to learn representations for proximity sensing. We report the normalized Decision Cost Function (nDCF) metric and analyze the differential impact of the various input signals, as well as discuss various challenges associated with this task. Link to paper |
|
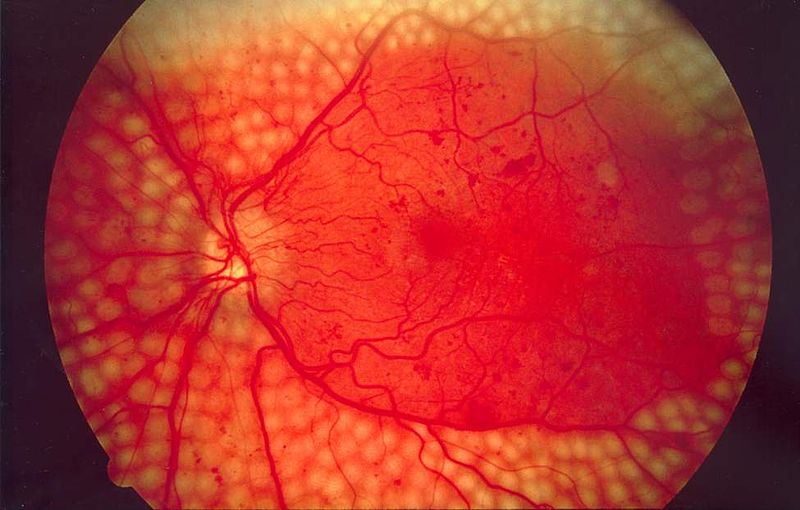
Project selected for the Google AI ML Mentorship Bootcamp as one among the 20 projects from around India Diabetic retinopathy is a condition suffered by people who have diabeties, which leads to permenent blindness if not treated in time. We propose a novel and efficient method to diagnose retinopathy from retinal fundas images using SVM and KNN algorithms. We also try out deep learning based solutions with grad cam scores to show the area of interest from the model point of view. GitHub repo here. |
|
Paper accepted at the Dravidian LangTech workshop at EACL 2021 and under review at the SN Computer Science Jounral (R&R with minor corrections) Over the past decade, we have seen exponential growth in online content fueled by social media platforms. Data generation of this scale comes with the caveat of insurmountable offensive content in it. The complexity of identifying offensive content is exacerbated by the usage of multiple modalities (image, language, etc.), code mixed language and more. Moreover, even if we carefully sample and annotate offensive content, there will always exist significant class imbalance in offensive vs non offensive content. In this paper, we introduce a novel Code-Mixing Index (CMI) based focal loss which circumvents two challenges (1) code mixing in languages (2) class imbalance problem for Dravidian language offense detection. We also replace the conventional dot product based classifier with the cosine based classifier which results in a boost in performance. Further, we use multilingual models that help transfer characteristics learnt across languages to work effectively with low resourced languages. It is also important to note that our model handles instances of mixed script (say usage of Latin and Dravidian - Tamil script) as well. Our model can handle offensive language detection in a low-resource, class imbalanced, multilingual and code mixed setting. Link to paper |
|
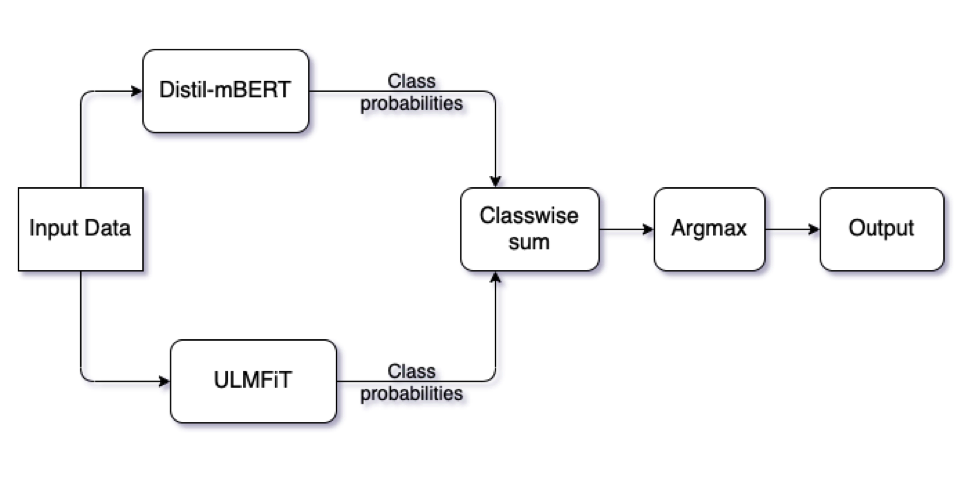
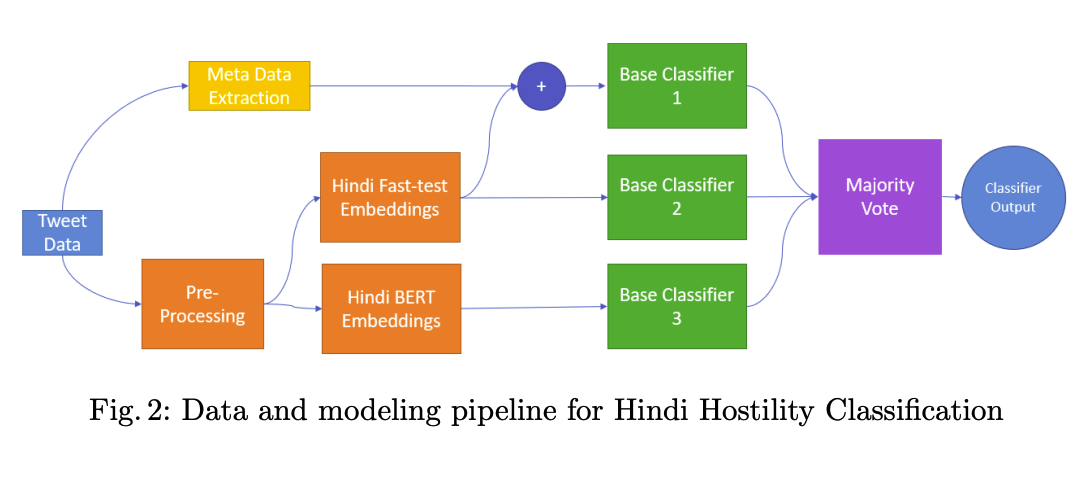
Paper accepted at the CONSTRAINT workshop at AAAI 2021 With the advent of social media, there has been an extremely rapid increase in the content shared online. Consequently, the propagation of fake news and hostile messages on social media platforms has also skyrocketed. In this paper, we address the problem of detecting hostile and fake content in the Devanagari (Hindi) script as a multi-class, multilabel problem. Using NLP techniques, we build a model that makes use of an abusive language detector coupled with features extracted via Hindi BERT and Hindi FastText models and metadata. Our model achieves a 0.97 F1 score on coarse grain evaluation on Hostility detection task. Additionally, we built models to identify fake news related to Covid-19 in English tweets. We leverage entity information extracted from the tweets along with textual representations learned from word embeddings and achieve a 0.93 F1 score on the English fake news detection task. Link to paper |
This template is a modification to Jon Barron's website. Find the source code to my website here.